If you’re involved in eDiscovery in any way, you’ve undoubtedly come across JSON files. These files increasingly act as the way in which we access and interact with digital evidence—especially as the limitations of screenshot evidence are highlighted by courts. But what exactly is a JSON file? And why are so many legal professionals absolutely frustrated with this format?
What Is a JSON File and What Is JSON Format?
JSON stands for JavaScript Object Notation and is a standard data interchange format that stores simple data objects and structures. Key to JSON’s versatility is the fact that it is text-based, human-readable, very lightweight, and easily editable through a text editor. JSON is often used in the world of Ajax Web application programming and is supported by many different programming APIs.
If you’re wondering what a JSON file looks like, here is an example of a Twitter feed that’s been transformed into a .JSON file.

As mentioned, the advantage of a JSON file is that it is text-based, human-readable, and lightweight—so a complicated Twitter stream full of text, images, videos, hashtags, mentions, emojis, and website links is transformed into a text-based file that is easy to share and view offline.
But there is a problem. The very text-based and lightweight nature of a JSON file that makes it so versatile also introduces issues. In certain key use cases—such as eDiscovery—JSON files can be incredibly frustrating and hard to work with.
JSON Files and eDiscovery
The JSON file shown above is taken from a collection of files Twitter provides when you request your data. It is the same kind of files you receive from platforms like Facebook and Instagram when you request your data—and is also similar to the files that a tool like Slack provides when an organization exports its data for legal or compliance purposes.
While these files do provide you with a readable and lightweight version of account data, there is an obvious problem: The content of a JSON file looks nothing like the original post or conversation.
Below is an example of what a very simple Slack message (“Hello World”) with a couple of emoji reactions (an astonished face 😲 and a facepalm emoji 🤦) looks like as a JSON file.

With a JSON file, messages and conversations are strung together and stripped of their context, including their associated media. Understanding even a short and basic message, like the one above, becomes tricky. Once you’re dealing with long conversations filled with GIFs, emojis, and links, it becomes almost impossible.
Not only do paralegals and other eDiscovery professionals need to decode this as they try to identify content that’s relevant to a legal matter—just imagine dealing with hundreds of thousands of Slack messages scattered across countless JSON files!—but they need to figure out how they can export, produce, and ultimately present this data in a way that a judge and jury will understand.
Wading through the JSON files of an entire Twitter account or Slack instance can take weeks, even months. It’s an incredibly manual process, and while you can search for certain keywords, this depends on you knowing exactly what words you need to look out for. The lack of context and visual elements also makes the process error-prone—it’s all too easy to overlook a valuable piece of content or inappropriate emoji.
And then there’s the issue of production. Social media posts and Slack conversations, like all forms of communications, are highly dependent on context. A JSON file is a poor representation of evidence that is often hard for a court or opposing counsel to understand—if a Facebook post or tweet is submitted as evidence, people will expect it to look similar to what’s on the live platform.
The JSON Alternative
If JSON files lack context and simple screenshots are not of evidentiary quality, what is the alternative? When it comes to collecting and preserving data for legal and compliance reasons, the best option is a dedicated solution, that allows the review and export of online data in its native format—while also providing the metadata and hash values needed to prove authenticity.
Pagefreezer for eDiscovery Review
Returning to the example of Twitter, here is what an account looks like inside the Pagefreezer dashboard:
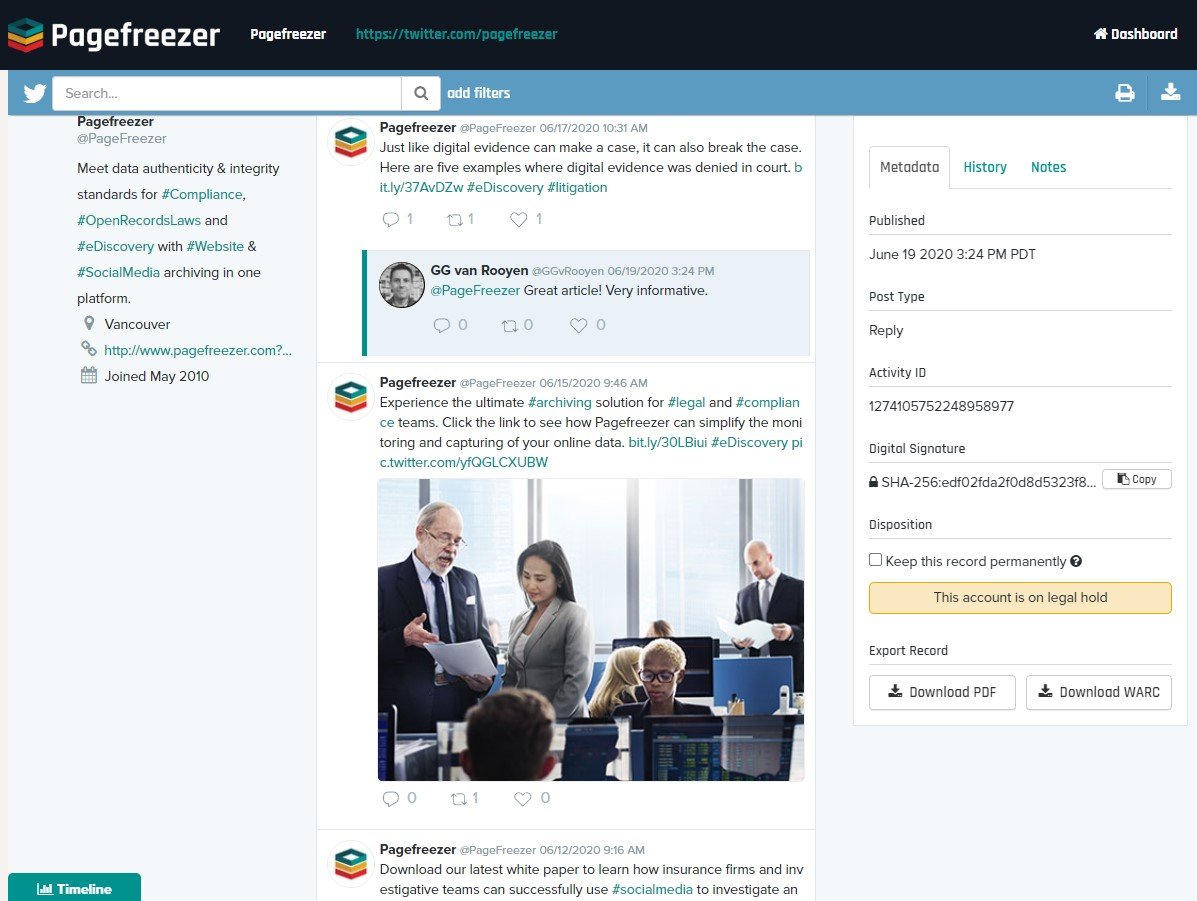
With Pagefreezer, legal and compliance professionals can:
- Retain all context—archived content has the same look and feel as the original platform
- Capture replies and view them in the context of the original tweet
- Capture direct messages
- See associated metadata
- Access deleted tweets that are no longer visible online
- Authenticate archived content through a hash value (digital signature)
- Easily export documents to PDF in defensible quality
- Place an account on legal hold to ensure nothing crucial is deleted from the archive
Similarly, Pagefreezer empowers legal teams through the automated collection and preservation of enterprise collaboration data, which helps them to easily meet eDiscovery requirements related to a tool like Slack or Workplace from Meta:
- Add users, channels, and groups to the Pagefreezer dashboard and then instantly view a live replay of all content
- Use advanced search to deliver relevant content across all archives, accounts, direct conversations, timelines, and groups
- Instantly select relevant content, add comments, and export files to local servers for eDiscovery purposes
- Export data to file formats such as PDF and WARC. Records are time-stamped and signed with a SHA-256 digital signature. All associated metadata is included in the export
- Place users and data on legal hold to prevent the deletion of crucial evidence
The video below shows what that looks like in practice:
Want to learn more? Download our case study to see how a leading global tech company streamlined early case assessment of evidence in Workplace from Meta. With 50,000 Workplace users and 300,000 (yes, 300,000!) groups, data volumes were overwhelming. But Pagefreezer helped simplify the process and greatly reduced workloads.