In litigation, discovery is the phase in which all parties must produce records and evidence relevant to a specific case. Thanks to the proliferation of electronically stored information (ESI), traditional discovery must now work alongside eDiscovery—a process that involves identifying, collecting, preserving, reviewing, and producing data that exists in electronic formats. These conditions have made the discovery process exponentially larger and much more complex.
Consider, for a second, just how many emails and instant messages are exchanged within a large organization or business every day. Add messages and social media posts, and multiply that by millions of people who spend part of each day online. The amount is staggering.
Within these petabytes of data, legal teams must:
- Find materials that might be relevant.
- Collect them.
- Retain them.
- Review the collected materials to decide whether or not each one is relevant to the legal case.
eDiscovery is an expensive and time-consuming process that has driven the development of sophisticated technology to support it and has led to the emergence of its own set of processes and jargon. To help close the information gap among parties involved in the process, we’ve compiled a glossary-like guide of eDiscovery terms and principles that may be useful for compliance professionals, IT and governance stakeholders, and records specialists.
What is eDiscovery?
The eDiscovery process is the collection of actions involved in collecting, preserving, reviewing, and producing electronically stored information (ESI) that might hold relevance in a legal case. The enormous task of combing through many terabytes of digital materials has earned eDiscovery its special place alongside traditional discovery.
Traditional discovery is the phase of litigation wherein the law requires involved parties to supply potentially relevant information to each other. The explosion of digital records and communications has ballooned the scope of traditional discovery, which used to consist of boxes and boxes of papers. Now, a party involved in a legal matter must supply other parties with enormous amounts of digital data.
What is Electronically Stored Information?
Electronically stored information, or ESI, is any data that has been created, used, stored or interacted with digitally. It includes data or information created, stored, preserved, or produced online. Even data that has been supposedly deleted still counts as ESI, and may need to be retained and accessed in the future if said content becomes relevant in a legal dispute or investigation.
ESI that often becomes involved in legal cases and investigations includes:
- Personally identifiable information (PII).
- Website content.
- Social media posts and interactions (such as comments, replies, and shares).
- Emails and instant messages (along with attachments).
- Collaboration documents.
- Cloud-based storage.
The eDiscovery Framework: Understanding the EDRM
What is the EDRM?
The EDRM, or Electronic Discovery Reference Model, is a widely accepted framework that outlines nine distinct stages of the eDiscovery process. Legal teams often use the EDRM to understand the demands of the eDiscovery process and to optimize their internal practices at every stage. It is not a prescriptive model, but rather a high-level overview of eDiscovery.
The illustration below provides a visual guide to EDRM:
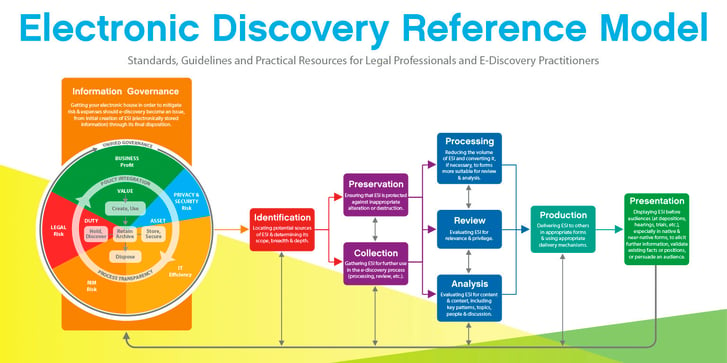
source: https://edrm.net/edrm-model/
What are the 9 Stages of the EDRM?
The nine stages of EDRM are:
- Information Governance (IG): IG describes an organization’s methods for capturing, storing, and using data. It also involves minimizing the risks of storing sensitive information and ensuring accountability for failures.
- Identification: Organizations are legally obligated to preserve any electronically stored information (ESI) that might pertain to a legal matter. “Identification” includes any activities—such as case reviews and interviews—that assist in identifying potentially relevant pieces of electronic information.
- Preservation: After an organization identifies crucial ESI, the next step is properly preserving that evidence for litigation. Failing to do so can result in what’s known as spoliation—the tampering or destruction of evidence.
- Collection: Once evidence has been preserved, the legal team needs a way to gather and present it in a way that’s defensible, meaning that the authenticity of the data should be expected to survive legal objections.
- Processing: In this step, the collected evidence is “cleaned up” ahead of attorney review. Data teams may delete irrelevant data, convert files, and ultimately collect everything in a single folder.
- Review: After ESI has been collected and processed, it must be reviewed by legal professionals to understand how it relates to the case at hand, if at all. Legal teams increasingly use AI technologies to review large amounts of data.
- Analysis: The analysis phase involves further evaluating ESI for a specific use in a legal matter. More than simply reviewing the information, analysis identifies key patterns, topics, and people involved in the case.
- Production: After gathering, reviewing, and analyzing relevant ESI, the evidence must be produced in a way that makes it usable during formal legal proceedings. This penultimate phase is called the production phase.
- Presentation: Once relevant legal evidence has been produced, all that remains is presenting it in ways a jury or judge can understand. Placing ESI in context during legal proceedings may involve implementing visual aids or, simply, typing up addenda.
What are the benefits of using the EDRM?
Companies with a proper understanding and utilization of the EDRM have a better chance of being litigation-ready and time-efficient. EDRM-reliant organizations also enjoy lessened financial risk from sanctions and spoliation, which describes non-compliance with standard rules of evidence and requests for production. These benefits can ultimately provide a legal team with stronger chances of success in and out of court.
Information Governance and Records Management
What is Information Governance?
Information governance is the way a business or organization organizes, protects, and derives value from data, as well as strategies to minimize risks of hosting potentially sensitive data.
Gartner defines information governance as:
“the specification of decision rights and an accountability framework to ensure appropriate behavior in the valuation, creation, storage, use, archiving and deletion of information. It includes the processes, roles, and policies, standards and metrics that ensure the effective and efficient use of information in enabling an organization to achieve its goals.”
To address the new challenges of information governance in the digital age, the Association of Records Managers and Administrators (ARMA) International created The Principles (also known as the Generally Accepted Recordkeeping Principles) in 2009 to help companies improve their approach to information governance. They were updated in 2025 and contain eight principles that serve as a standard of conduct.
The eight principles illustrate how modern enterprises should:
- Oversee information management to ensure accountability within the organization.
- Manage information in an open and transparent way.
- Guarantee the authenticity and reliability of information.
- Classify and protect information that should not be accessible to everyone.
- Comply with all relevant recordkeeping regulations.
- Maintain the availability and accuracy of information.
- Retain information for regulatory, legal, and historical requirements.
- Dispose of information no longer required.
Information governance is an important element in eDiscovery as well, because without these best practices in place, an organization will not be able to easily and quickly identify, preserve, or retain the correct information should a legal matter arise.
👉 For insights into how enterprises can organize and leverage their data and implement the Information Governance Maturity Model, check out our blog.
What is the Difference Between Information Governance and Records Management?
Although records management and information governance are sometimes used synonymously—and the two concepts do, admittedly, share a similar purpose within the average organization—there are several important differences.
To better understand these differences, it can be helpful to look at how ARMA defines the two terms:
ARMA’s Information Governance Definition
A strategic framework composed of standards, processes, roles, and metrics that hold organizations and individuals accountable to create, organize, secure, maintain, use, and dispose of information in ways that align with and contribute to the organization’s goals.
ARMA’s Records Management Definition
Records management is the systematic management of records and information through their various life cycles. It includes the analysis, design, implementation, and management of manual and automated systems regardless of format or medium.
At first glance, these definitions seem similar, but a careful reading reveals key differences between them.
While records management tends to focus on the systems used to manage the lifecycle of documents, information governance approaches data at a higher level, from a strategic perspective.
Consider that a few decades ago, records management referred to the management of discrete (and largely physical) documents. The proliferation of online data sources has created a landscape too complex for traditional records management alone. Enter information governance, which places a great emphasis on IT (information technology) and automated processes.
Finally, as information governance continues to broaden its view of records management, it also provides the opportunity to use information in more strategic ways. Not only can it be crucial for mitigating risk within an organization, but it also makes it easier to use large volumes of unstructured data to the company's benefit. Robust information governance models and processes benefit organizations in multiple eDiscovery phases.
Understanding Modern Data Types
What is Unstructured Data?
Unstructured data describes data that does not exist within a structured or organized format or database. Approximately 80 percent of data in modern organizations qualifies as unstructured.
Unstructured data can come in the form of:
- PDFs.
- Text documents.
- Spreadsheets.
- PowerPoint presentations.
- Images.
- Videos.
- Audio files.
Digital Communications May Qualify as Unstructured Data
Communication tools that modern enterprises use—email, mobile text messages, social media, and enterprise collaboration platforms—also fall within the realm of unstructured data (though they do have some structure thanks to metadata). Given how much communication takes place, these sources generate massive amounts of data that organizations aren’t always sure how to handle.
How Does Unstructured Data Create Legal Risk?
The biggest reason unstructured data creates legal risk is that organizations have not devoted sufficient resources to properly analyze it and place it in databases with controlled access. This lack of centralized access can present security risks and vulnerabilities, as can the sheer volume of unstructured data.
How Much Unstructured Data Does Your Organization Have?
Companies often do not have a clear idea of how much unstructured data is floating around on their servers and in their data lakes. As the number of unknown variables surrounding particular data goes up, the greater the chances that bad actors can access it.
How Do You Collect Unstructured Data for eDiscovery?
Collecting unstructured data for eDiscovery typically requires specialized software that automatically gathers data by keywords and content analysis. Data filtering is also key when working with large amounts of unanalyzed, unstructured data.
One of the most important considerations in eDiscovery is collecting data that is legally defensible. Screenshots and native software backups lack metadata, hash values, and a clear chain of custody—all features proving that the selected evidence is authentic.
Robust archiving tools that capture content in the WORM (write once, read many) format can save organizations time, money, and stress.
When Does the Duty for Organizations to Preserve ESI Begin?
Using legal terms, the duty to preserve electronically stored information (ESI) in a potential legal matter arises when potential legal parties have a “reasonable anticipation of litigation.” While the reasonable anticipation point differs based on the specific circumstances of each case, common triggers include:
- Subpoenas.
- Verbalized legal threats.
- Internal investigations within a company.
- Regulatory inquiries.
- Notice to Sue letters.
- Filing of complaints with government agencies.
Why the Duty to Preserve ESI Matters in eDiscovery
Delaying data preservation in a legal matter can result in judicial fines or attorneys’ fees awards if a judge determines that spoliation has occurred. Without prompt action, legal parties may simply miss out on collecting evidence that could help their case or have their evidence challenged by the other side.
Preserving Defensible Evidence
What is a Legal Hold?
A legal hold, also known as a litigation hold, is a notice issued within an organization to preserve all relevant information and data associated with legal matters or investigations.
Such an action typically originates from an organization’s legal department and instructs custodians and data stewards:
- Not to delete electronically stored information (ESI).
- Discard archived documents that may be potentially relevant to an upcoming legal matter.
Legal hold notices should be succinct, straightforward, and clear to all recipients. Information included in these notices often includes:
- The subject matter of the information to be preserved.
- The types of materials employees should archive or preserve.
- Applicable time frames.
- The appropriate company contact to receive inquiries.
- Ways to ensure data custodians do not modify or delete potentially relevant content.
Consequences of Ignoring Legal Holds
Organizations and businesses may face serious consequences if they fail to properly preserve pertinent content. Such consequences include financial penalties, default judgments against the firm, or outright dismissal of the legal matter.
What is Chain of Custody?
Chain of custody describes the verified handling of evidence in chronological order; each person or entity that has control (custody) over the content at any given point is a link in the “chain.”
Chain of custody also provides a clear record of how particular evidence was stored, transferred, handled, and formatted.
Legally defensible evidence (including electronically stored information) in cases must have a valid, authenticated chain of custody. Without this, you leave your organization vulnerable to various legal obstacles and sanctions for spoliation.
Organizations verifying the chain of custody before courts must answer three questions:
- How was the evidence collected?
- How did you preserve the evidence?
- Who handled the evidence?
What Happens if You Fail to Preserve ESI?
Failing to preserve relevant ESI (electronically stored information) in legal matters can expose an organization to civil penalties or, at the very least, a disadvantage in court. As soon as organizations or companies reasonably anticipate litigation, they have a duty to preserve potentially relevant information, including ESI.
Failure to preserve ESI can result in:
- Civil fines.
- Adverse legal outcomes, such as case dismissal or summary judgment.
- Judges instructing juries to disregard evidence because of questions surrounding authenticity.
- Damage to a firm’s reputation.
If a spoliation claim is being considered, the court must also determine whether the spoliation was intentional or the result of neglect.
Courts typically use the “reasonable person” standard in deciding such claims, wherein they determine whether a reasonable person would have preserved evidence in the same situation. Intentional destruction of evidence may result in more severe legal sanctions than neglectfully failing to preserve evidence.
What is Evidence Spoliation?
Evidence spoliation is the accidental or intentional destruction or corruption of evidence during a legal matter. At a certain point—when litigation becomes reasonably foreseeable or anticipated—parties in a particular legal case have the obligation to save and preserve potentially relevant materials. This obligation to preserve evidence often comes after someone within an organization sends out a legal hold notice to everyone else.
Because digital content can be deleted, edited, or corrupted in a matter of seconds, companies and organizations must act diligently and promptly to preserve electronically stored information (ESI).
Why Evidence Spoliation Matters in Court
If a court determines that a party has committed spoliation, a number of adverse consequences may be imposed. A judge might dismiss the case, rule in favor of the other party before either side gets to argue their case (summary judgment), or rule that the presentation of certain evidence or ESI should not be allowed in the case.
Producing and Managing ESI
What is a Request for Production of Documents?
A request for production of documents is an action initiated by a legal party during the discovery phase to gain access to documents, electronic data, and physical items held by an opposing party. The aim is to gain insight into any relevant evidence that the opposing party holds.
The proliferation of eDiscovery and ESI (electronically stored information) in modern legal matters has made document production vastly more complicated, mainly due to the large amounts of data (structured and unstructured) associated with companies and organizations.
What Companies Should Know about Document Production Requests
However, simply sifting through mountains of data is not the only challenge. Parties in legal cases must take care to preserve original data and ensure the ESI that they DO collect is free from alterations. To be legally defensible, ESI must typically be accompanied by metadata and hash values, among other properties. Achieving that can be incredibly difficult without purpose-built software.
Are Deleted Emails, Social Media Posts, or IMs Discoverable?
Yes, deleted ESI (electronically stored information), such as instant messages, emails, and social media content, is generally discoverable during a legal matter. Although the custodians or owners of digital content might hit “delete” or “move to recycle bin” on the ESI, there is almost always some trace of the data after the fact. Either way, this deleted content can still be subject to requests for production and ediscovery.
Because courts often compel legal parties to produce deleted or edited ESI, organizations in highly regulated industries need software that automatically captures data in the WORM (write once, read many) format. In-app archiving options and internal system backups rarely store data in legally defensible ways.
Failure to properly preserve evidence can result in court sanctions, fines, and other serious consequences for companies and organizations that engage in spoliation.
Can Website Content Be Used as Evidence in eDiscovery?
Yes, website content, including past versions of specific pages, is commonly considered to be evidence in eDiscovery. Websites represent a common type of electronically stored information (ESI) that parties request to help resolve legal matters.
Screenshotting website content may seem like the quickest way to save ESI in anticipation of litigation, but making screenshots of every page on some websites can be especially cumbersome and tedious. To further complicate matters, legal parties may challenge the authenticity of screenshots because images can be easily altered with simple digital tools. Even CMS backups and native-app archiving capabilities do not, generally, provide legally defensible evidence that can withstand legal challenges.
Can Social Media Be Used in eDiscovery?
Yes, social media content frequently gets requested by parties in the eDiscovery phase of legal cases. Posts, comments, and replies from companies’ official profiles may qualify as business communications and factor into legal disputes and investigations. It’s also important to capture the entire context behind specific social media interactions and threads.
Because Instagram, X, Facebook, and other social media applications offer native archiving options, users may assume these capabilities will suffice when asked to produce ESI (electronically stored information) in legal matters. That’s not often the case, however, as these archiving capabilities often lack:
- Important metadata.
- Hash values or digital signatures that prove authenticity.
- Native context and formatting.
- The WORM (write once, read many) format.
- Other assurances that ESI is properly archived in its original form and protected from edits.
Data Retention vs. Preservation
What is Data Retention?
Data retention is the collective term for the policies and practices organizations use to store digital information. It is an ongoing process and one of the pillars of broader “records management” and information governance policies.
Many organizations and businesses have both internal data retention policies and external requirements for saving information. These external requirements may come from:
- The US federal Freedom of Information Act (FOIA).
- The European Union’s GDPR (General Data Protection Regulation) law.
- Securities and Exchange Commission (SEC) requirements for organizations in the highly regulated financial industry.
- State-level Open Records Laws (often referred to as Sunshine Laws).
To manage retention and adhere to best practices, businesses often implement systems that automatically dispose of data in accordance with a personalized retention schedule.
Why Over-Retention of Digital Data Matters
Over-retention of online information, while well-intentioned, can actually make data less secure. It’s generally more difficult (and more expensive) to effectively preserve and manage large amounts of ESI (electronically stored information). Simply having more data also means bad actors have more opportunities to break into repositories. Dealing with duplicate data can also make eDiscovery more cumbersome.
What is Data Preservation?
Data preservation is the act of organizing data and preparing it for possible presentation in an upcoming legal matter. It goes beyond data retention, which is the practice of saving relevant digital information in internal databases.
The US Federal Rules of Civil Litigation (FRCP), 37(e) requires that ESI (electronically stored information) be preserved when parties can reasonably anticipate litigation. “Reasonable” anticipation might include:
- Communications from the other side’s counsel.
- Service of a subpoena.
- Media reports of current or potential investigations and legal matters.
- Official notifications from internal or external agencies.
Data preservation typically requires collaboration across multiple company departments, depending on the scope and relevant content of a legal matter. Furthermore, organizations must preserve ESI in a way that ensures the evidence’s authenticity would survive court challenges.
What is the Difference Between Backups and eDiscovery Archives?
Despite their similarities, system backups and eDiscovery archives for organizations serve distinct purposes. Both have the same basic aim of saving past versions of websites and other types of electronically stored information (ESI), but they differ in critical areas:
- Duration: Specific versions of website backups only last for a few days or weeks before a newer one overwrites them. By contrast, true archives for eDiscovery purposes are designed to continuously save full, immutable versions that last until organizations intentionally dispose of them.
- Purpose: Organizations typically use system backups for internal purposes, i.e., to provide plug-and-play versions if the current site crashes. Content in eDiscovery archives has properties (such as metadata and audit-ready compliance trails) that make it legally defensible and in compliance with government regulations.
- Searchability: eDiscovery archives exist within indexed, searchable databases that make data retrieval easy. Backups, on the other hand, are not known for robust indexes or the ability to search historical content.
Making ESI Searchable and Reviewable
What is Optical Character Recognition (OCR)?
Optical Character Recognition, or OCR, is the electronic conversion of handwritten content, ink-printed text, or image-only digital documents into a machine-readable, searchable text format.
OCR software can save organizations a large amount of time in eDiscovery by identifying and converting text characters from potentially relevant materials, such as:
- Physical contracts.
- Typed letters.
- JPEGs of photographed documents.
- Image-only PDFs.
After conversion into OCR, users can search for and retrieve documents much the same way they’d find excerpts of text in word-processing software. Rather than manually going through individual image documents, companies can save money and resources during eDiscovery by executing a full-text search.
The Challenges of Optical Character Recognition
While incredibly useful, the technology can also be challenging to implement due to several factors. For instance, varying fonts and letter-forming methods can make character identification difficult without human involvement. Additionally, poor image quality can hamper machine conversion.
What is Technology-Assisted Review?
Technology-assisted review (TAR) is the process of “teaching” machine-learning applications to analyze, score, and prioritize documents during specific eDiscoveries. It combines human expertise with the efficiency of ever-advancing AI technologies.
How Does Technology-Assisted Review Work?
Let’s say an organization needs to analyze x amount of data for an upcoming legal case. The ones with the ability to make the determination of relevancy and priority for the documents will review a representative sample of data and export the results to machine-learning systems. Based on what the machine has “found out” about which types of documents and properties to prioritize, it will review the remaining data.
By imposing guardrails and expectations on the automated system, parties engaging in eDiscovery can save an enormous amount of time and resources through TAR. Using TAR for text-heavy files generally delivers the highest ROI.
TAR can provide statistics, categorization, and other reporting data efficiently and with reduced opportunities for errors. Users can make periodic adjustments as needed.
Authenticating Digital Evidence
How Can You Prove Digital Evidence Wasn’t Manipulated or Tampered With?
Proving digital evidence is free from manipulation or tampering requires the confluence of several factors and circumstances. Three important items in data authentication are:
1. Metadata, which is data that describes digital files and classifies them in easy-to-retrieve ways. It organizes data by specific properties so users can search for specific terms and retrieve them later.For example, a collaborative text-based document’s metadata may answer the following questions:
- Who created the document?
- Who has or has had access to the document?
- When was the document created and edited?
- What type of file is the document?
2. Hash values, which are unique codes that correspond to particular files and documents. Hash values only go one way—you cannot alter hash values after you run data through an algorithm, making them immensely useful for verifying data’s originality and authenticity.
3. Chain of custody, otherwise known as the verified trail of users who had access to a particular file or document and details about each user’s interactions with the data.
What Are Hash Values?
Hash values are unique sets of characters that correspond with one (and only one) piece of digital data. What’s particularly useful about hash values is that fraudsters, scammers, and other bad actors cannot derive original data from hash values—they only go one way. It’s like a fingerprint for data, and any discrepancies between the true hash value and a character set purporting to be the true hash value will set off a red flag that something is wrong.
A small change to the input will result in a dramatic change to the hash value on the right. This makes it nearly impossible to alter a digital file without changing the hash value and making it clear that the data has been tampered with.
How Do You Get a Hash Value for Your Digital Data?
Users can obtain a hash value of data by running it through a hash algorithm, such as SHA-256 (the widely accepted standard for modern organizations). Because of this, many data sets that require strong security, such as passwords, are hashed using the SHA-256 algorithm. SHA-256 hashes also help in eDiscovery by verifying the authenticity of discoverable data.
Understanding Hash Values (Visual Guide)
Below, you can see sample hash values for a simple word and sentence, along with ways the values dramatically change with simple alterations to the inputs.

A small change to the input will result in a dramatic change to the hash value on the right. This makes it nearly impossible to alter a digital file without changing the hash value and making it clear that the data has been tampered with.
Source: https://en.wikipedia.org/wiki/Cryptographic_hash_function
What is Metadata?
Metadata (commonly called “data about data”) is the subsurface data underneath digital files that tells the full story of each piece of data. It provides important fundamental details about files, such as:
- Authorship.
- Date of creation, modification, and access.
- Geolocation information.
- File size and type.
- Validation and access rules.
Screenshots of Metadata are Insufficient in eDiscovery
Viewing metadata is relatively easy, which leads some to assume that pictures of metadata are enough to pass muster in court. However, screenshots are not immutable, meaning they can be altered and, as a result, corrupted. In addition to its lack of legal defensibility, screenshotting can take an inordinate amount of time for organizations.
What Does Metadata Look Like?
Check out the relatively large amount of metadata generated from a short post on X (formerly Twitter):

An example of what the metadata related to a simple tweet looks like.
Modern Communication Challenges
What Role Do Emojis Play in eDiscovery?
As emojis become more thoroughly integrated into everyday communications—even in corporate communications—data managers, legal professionals, and others involved in eDiscovery must take steps to preserve them alongside crucial context to use them as proper evidence.
Many emojis, at least in isolation, can be open to interpretation. Could a kissing emoji communicated between two longtime coworkers indicate an innocent (though cheeky) comment, or might it be evidence of an intimate relationship between a manager and their subordinate? Would it make a difference if the kissing emoji were immediately followed by a heart emoji?
Challenges Involved with Interpreting Emojis
That hypothetical circumstance illustrates both the importance of emojis in communication AND the potential challenges of using them as evidence. It’s critical for your archiving software to capture emojis exactly as they appear, as well as the entire communication threads in which they appear. Emojis themselves may not always be the most important electronically stored information (ESI) in eDiscovery, but they can go a long way in showing the intent of a message sender.
Operational eDiscovery FAQs
Who is Responsible for eDiscovery Within an Organization?
eDiscovery, the pre-trial phase involving the exchange of ESI (electronically stored information) between legal parties, does not fall on a single person or department, but on multiple.
In many, if not most, cases, company departments that play a part in this legal phase include:
- IT. The information technology department executes the crucial actions of eDiscovery after receiving direction from the legal team. IT professionals take steps to save, preserve, analyze, and present potentially relevant ESI.
- Legal. Whether in-house or external, the legal team serves as the coach for the eDiscovery process and identifies the client's higher-level strategy. It ensures the relevant stakeholders receive notice of legal holds and that everyone follows the appropriate evidence rules.
- Compliance. An organization’s compliance team may play a crucial role in eDiscovery, double-checking that archived evidence is tamper-proof and has the appropriate characteristics to survive potential challenges from the other legal party.
- eDiscovery liaison. Due to the sheer amount of data most modern organizations must contend with and the complexity involved with wrangling properly archived data, the eDiscovery liaison is becoming adopted more and more. Liaisons can also help ensure that shared responsibilities and processes run smoothly.
What is Early Case Assessment?
In the context of eDiscovery and electronically stored information (ESI), an early case assessment is a preliminary analysis of existing evidence to help legal teams understand their prospects of success in an upcoming case. The earlier in the EDRM process teams can start the early case assessment, the more useful the assessment can be.
With early case assessment software, legal parties can get a snapshot of potentially relevant ESI, the costs of preserving the entirety of the evidence, and related costs. It can help save organizations valuable time and money by filtering out irrelevant evidence and quickly creating a cost-benefit analysis for going to trial or settling. Today’s early case assessment solutions use keyword targeting, data visualization, and AI features to maximize efficiency.
How Long Does the eDiscovery Process Take?
The duration of eDiscovery depends on the particulars of each case—complexity, number of parties, amount of data that must be analyzed and processed—but it’s not uncommon for eDiscovery to take more than a month. For especially complex cases, a year or more may be needed for all sides to get the information they need.
Common Bottlenecks in eDiscovery
A number of junctures within eDiscovery can cause delays and frustrations for the parties involved. Bottlenecks can occur:
- After the first call goes out from legal to retain and preserve data. Many organizations lack pre-existing archiving technologies to make data easily searchable and retrievable.
- When IT professionals do not have robust reviewing tools to efficiently analyze the relevancy of existing data.
- If organizations have not made previous efforts to secure potentially sensitive data.
- When deleted data has not been properly archived.
- If organizations do not devote the appropriate amount of time, personnel, or money to eDiscovery.
- When data custodians misidentify the amount of ESI (electronically stored information) that needs to be analyzed.
How Much Does eDiscovery Cost—and Why?
Legal teams and data professionals charge varying rates for eDiscovery, with set hourly rates for some tasks and highly variable rates for others. For instance, firms might charge $100-300 per hour for analysis of retained content and $500-$1,500 per social media account that needs to be archived and reviewed.
The amount each organization will spend on eDiscovery depends on factors like:
- Case complexity.
- Amount of data.
- State of existing electronically stored information (ESI).
- Nature of personnel assigned to eDiscovery.
- Software used to complete the process.
In general, the quality of data retention and archiving pre-litigation can have a dramatic impact on eDiscovery costs and timelines, as can information governance. ESI that’s already archived in the WORM (write once, read many) format gives organizations a massive head start in eDiscovery, for instance, while firms that need to scour inboxes and disparate databases for potentially relevant evidence frequently find themselves scrambling.
Common eDiscovery Mistakes Organizations Make
Because data and data preservation technologies are constantly shifting, many organizations find themselves on the near side of the learning curve when starting the eDiscovery process. As a result, there are common mistakes that many first-timers make.
Five common eDiscovery mistakes include:
- Relying on screenshots. Taking screenshots of every piece of potentially relevant evidence is inefficient and prone to human error. What’s more, screenshots often fail to withstand authenticity challenges in court because they can be easily edited.
- Over-retention of data. Some organizations think that retaining and preserving large amounts of data that may not be relevant is erring on the side of caution, but over-retention can cause its own problems. Trying to tackle more data than is practicable can devour time and resources, leaving little time for review and production, as well as put your organization at additional risk if systems are accessed by bad actors.
- Manual processes. No matter how frequently data custodians archive ESI (electronically stored information), manual processes will always be less thorough and accurate than automated software that continually archives data in the right formats.
- Late legal holds. Organizations have an obligation to save data as soon as they reasonably anticipate the possibility of litigation. To prevent inadvertent spoliation, legal teams need to send out legal hold notices as soon as possible. Consequences of spoliation include fines and the striking of potentially crucial evidence.
- Poor documentation. Companies in highly regulated industries must keep up with a number of federal and industry-specific regulations, including FOIA, state open records laws, and SEC and FINRA rules. Disputes, investigations, and legal matters in those arenas are high-stakes, and insufficient data storage and documentation can be devastating.
Related Resources
Want to learn more about eDiscovery? Check out our additional resources:
- Essential Guide to Online Investigations
- Online Data Archiving Compliance Guide
- ESI Risk Management & Litigation Readiness Report